
StreamKL: divergencia KL rápida y eficiente para destilación de atención
StreamKL reduce el consumo de memoria de O(N²) a O(1) y acelera hasta 43x la destilación de atención en GPUs. Ideal para modelos con contexto largo.
StreamKL reduce el consumo de memoria de O(N²) a O(1) y acelera hasta 43x la destilación de atención en GPUs. Ideal para modelos con contexto largo.

StreamKL acelera hasta 43x la divergencia KL en destilación de atención, reduciendo memoria de O(N²) a O(1) en GPU. Ideal para contextos largos.
Descubre cómo el método RECAP evita que los modelos de razonamiento olviden capacidades generales durante el entrenamiento RLVR, preservando percepción y

¿La divergencia KL es un buen indicador de calidad en modelos de lenguaje cuantizados? Descubre por qué falla en la zona silenciosa y cómo afecta al despliegue.
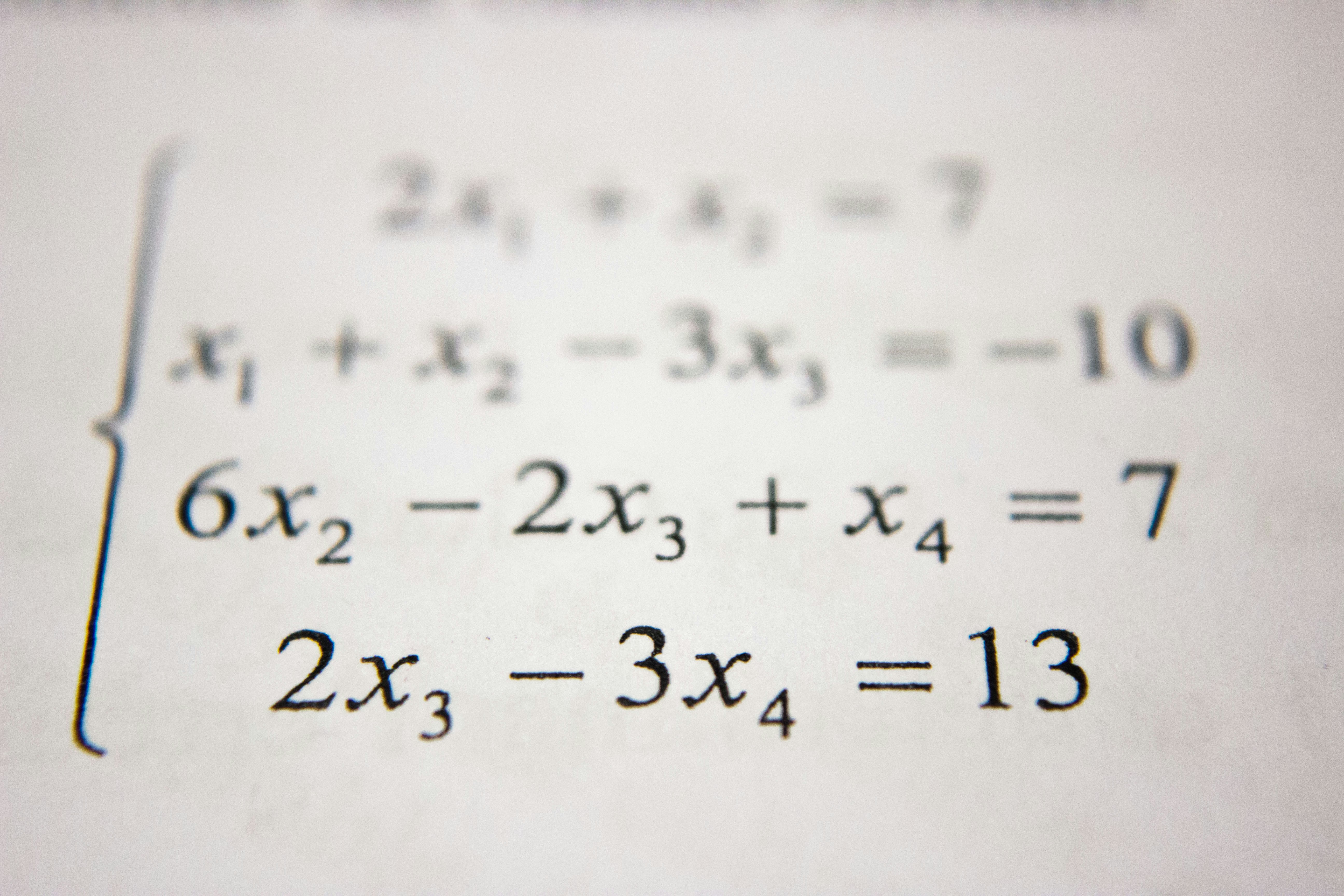
Descubre cómo la nueva Safe KL Divergence permite optimizar LogSumExp de forma eficiente con métodos estocásticos, mejorando transporte óptimo y DRO.
El nuevo enfoque PFOM unifica flujo, difusión y saltos en modelos generativos usando el operador de Perron-Frobenius. Aceleración Nesterov y divergencia KL.

Descubre cómo el modelado basado en distribución supera a Gemini en precisión y calibración al predecir eventos en programas Go concurrentes. Un enfoque
Los regularizadores deterministas MMD, KSD y KL en la hiperesfera mejoran la estabilidad y convergencia en aprendizaje autosupervisado.
Descubre PFOM: un marco generativo que unifica flujo, difusión y saltos vía operador de Perron-Frobenius. Convergencia acelerada con Nesterov.
Descubre cómo los regularizadores deterministas en la hiperesfera eliminan la varianza estocástica, mejorando la convergencia y la geometría del espacio
Mejora la convergencia de tus modelos generativos con DFM: nuevas cotas KL con dependencia dimensional reducida y garantías Wasserstein. Lee más.

Nuevos límites de convergencia para Diffusion Flow Matching con mejoras en KL y Wasserstein. Análisis teórico avanzado para modelos generativos.

¿Sabías que reintroducir el contexto a un modelo destilado puede empeorar su rendimiento? Descubre cómo un ligero regularizador lo evita.

Los tokens FSQ son óptimos para difusión continua en datos categóricos. Este estudio demuestra que superan a modelos LLM en TTS siendo más pequeños y rápidos.

Los modelos de GNN calibrados son vulnerables a ataques adversariales. El marco UGCA revela cómo aumentar el error de calibración manteniendo la precisión. ¡Conócelo!